Journal Watch is an on-going project where we track the representation of female scientists published in the ‘Top 4’ neuroscience journals.
Journals that are included in the analyses:
– The Journal of Neuroscience
– Neuron
– Nature Neuroscience
– eNeuro
The following charts include data collected between 2019 and 2021.
To find out more about our methodology and links to older Journal Watch posts, please see our methods documentation here.
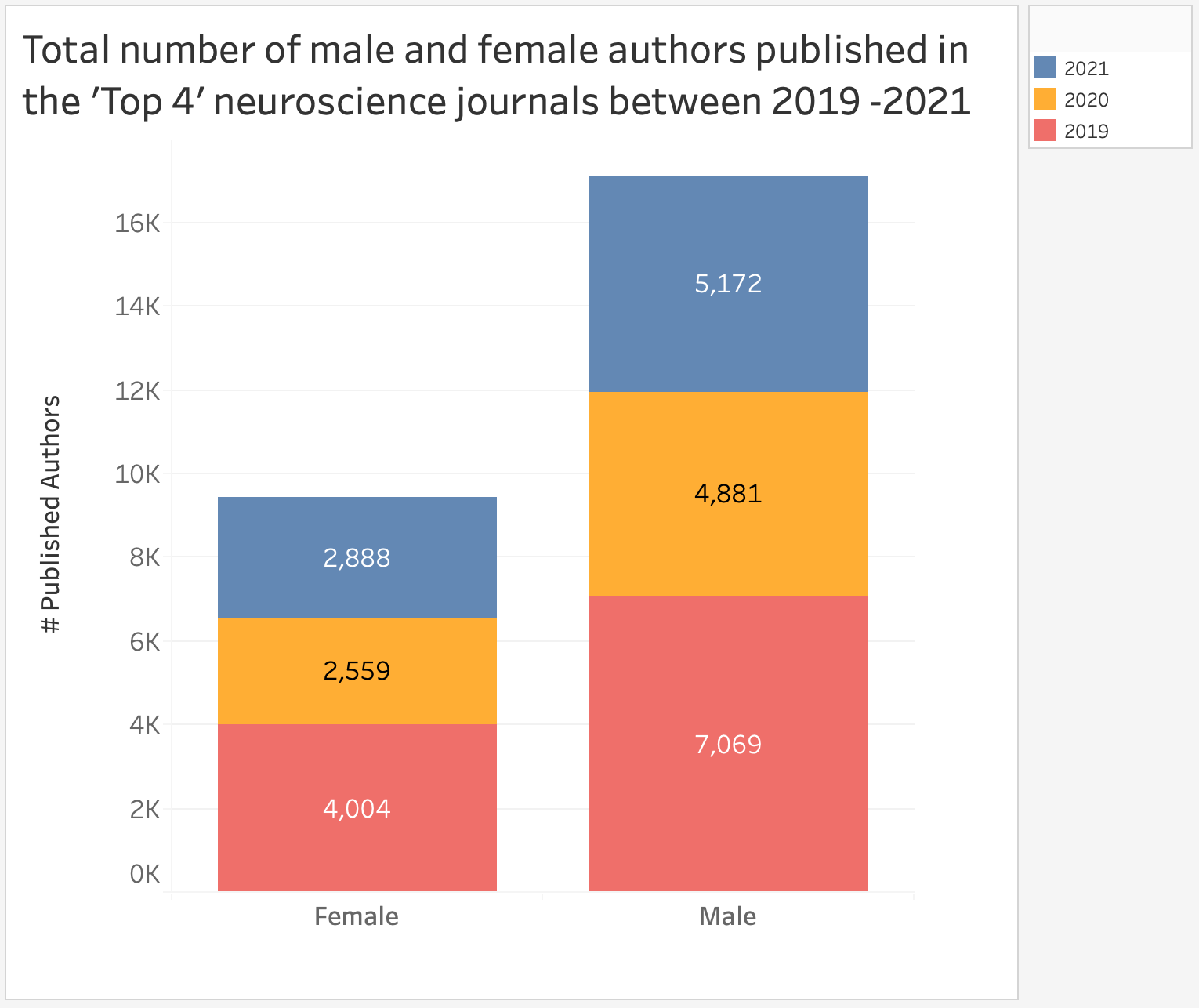
The next chart shows a breakdown of female authors published in each journal between 2019-2021:

Finally, we see that among all last author positions, only 24% were female authors:

